Recursos de interés
Artículo: Tidy Data. Wickham, H. (2014).
Sitio sobre exploración visual de datos: Visual Data Exploration - UC Business Analytics R Programming Guide.
Datos utilizados durante el curso: Procesamiento de datos con R - datos.
Trabajo previo
Se recomienda leer:
Conjuntos de datos utilizados
Los conjuntos de datos utilizado en los siguientes ejemplos y ejercicios pueden cargarse en data frames con la función read.csv() y visualizarse con la función View().
Puntos de muestreo de cobertura y uso de la tierra
Este conjunto de datos fue generado como parte del Ejercicio de Monitoreo por Puntos del Sistema de Monitoreo de Cobertura y Uso de la Tierra y Ecosistemas (Simocute).
# Carga de datos en un data frame desde un archivo CSV
puntos_muestreo <-
read.csv(
file='https://raw.githubusercontent.com/curso-r-simocute/datos/main/puntosmuestreo-coberturauso-tierra/pnt_csv.csv'
)
# Despliegue de los datos
View(puntos_muestreo)
Paquetes utilizados
Pasos iniciales
Visualización de conjuntos de datos en formato tabular
Como primer paso, pueden observarse los datos en un formato tabular. Una manera sencilla de hacerlo es con la función View(), la cual presenta un data frame en un formato similar al de una hoja de cálculo.
# Despliegue de un data frame en una tabla
View(puntos_muestreo)
Para visualizar los datos en la consola de R (o RStudio), pueden utilizarse las funciones:
- head(): despliega las n primeras observaciones de un data frame.
- tail(): despliega las últimas n observaciones de un data frame.
En el siguiente ejemplo, se utiliza head() en combinación con la función sort() para primero ordenar los valores del vector correspondiente a la columna sample_id y posteriormente desplegar los n primeros.
# Despliegue de los n primeros valores ordenados de la columna sample_id
head(sort(puntos_muestreo$sample_id), n=10)
[1] 526016793 526016794 526016795 526016796 526016797 526016798
[7] 526016799 526016800 526016801 526016802El mismo resultado puede obtenerse con las siguientes funciones de Tidyverse contenidas en el paquete dplyr:
- select(): selecciona un subconjunto de variables de un data frame.
- arrange(): ordena los registros de un data frame.
- slice_head(): selecciona los n primeros registros de un data frame.
En el siguiente ejemplo, note el uso del operador %>% (llamado pipe) para encadenar procesos y comunicar datos entre estos.
# Despliegue de los n primeros valores ordenados de la columna sample_id, mediante funciones de dplyr (Tidyverse)
puntos_muestreo %>%
select(sample_id) %>%
arrange(sample_id) %>%
slice_head(n=10)
sample_id
1 526016793
2 526016794
3 526016795
4 526016796
5 526016797
6 526016798
7 526016799
8 526016800
9 526016801
10 526016802 Ejercicio:
a. Con base en el ejemplo anterior, despliegue los 20 últimos valores ordenados de la columna sample_id, mediante funciones de dplyr (Tidyverse).
b. Obtenga el mismo resultado del ejercicio a., pero utilizando las funciones tail() y sort().
Información resumida sobre un conjunto de datos
Las dimensiones de un data frame pueden obtenerse con las funciones:
- nrow(): cantidad de registros de un data frame.
- ncol(): cantidad de columnas de un data frame.
- dim(): cantidad de registros y columnas de un data frame.
# Cantidad de registros
nrow(puntos_muestreo)
[1] 26125
# Cantidad de columnas
ncol(puntos_muestreo)
[1] 44
# Dimensiones del data frame
dim(puntos_muestreo)
[1] 26125 44Para visualizar solamente la lista de los nombres de las columnas de un data frame, puede usarse la función names().
# Despliegue de los nombres de columnas de un data frame
names(puntos_muestreo)
[1] "X" "plot_id"
[3] "sample_id" "lon"
[5] "lat" "flagged"
[7] "analyses" "email"
[9] "collection_time" "analysis_duration"
[11] "imagery_title" "imagery_attributions"
[13] "sample_geom" "pl_plotid"
[15] "T1.COBERTURA" "X1000.Veget.T1"
[17] "X2000.Sin.veg.T1" "X3000.Agua.T1"
[19] "X4000.Nub.somb.T1" "T1.USO"
[21] "X1000.MC.bos.T1" "X2000.Agricul.T1"
[23] "X3000.Ganad.past.T1" "X4000.Zon.hum.T1"
[25] "X5000.Infraest.T1" "X6000.Otras.tier.T1"
[27] "X7000.No.clasif.T1" "T2.COBERTURA"
[29] "X1000.Veget.T2" "X2000.Sin.veget.T2"
[31] "X3000.Agua.T2" "X4000.Nub.somb.T2"
[33] "T2.USO" "X1000.MC.bos.T2"
[35] "X2000.Agricul.T2" "X3000.Ganad.past.T2"
[37] "X4000.Zonas.humed.T2" "X5000.Infraest.T2"
[39] "X6000.Otras.tier.T2" "X7000.No.clasif.T2"
[41] "Ob.T1.COB" "Ob.T1.USO"
[43] "Ob.T2.COB" "Ob.T2.USO" La función str() (de structure) muestra también los nombres de las columnas, junto con el tipo de datos y una muestra de los datos en cada una.
# Despliegue de la estructura de un data frame
str(puntos_muestreo)
'data.frame': 26125 obs. of 44 variables:
$ X : int 1 2 3 4 5 6 7 8 9 10 ...
$ plot_id : int 138528311 138528311 138528311 138528311 138528311 138528311 138528311 138528311 138528311 138528311 ...
$ sample_id : int 526032918 526032919 526032920 526032921 526032922 526032923 526032924 526032925 526032926 526032927 ...
$ lon : num -84.2 -84.2 -84.2 -84.2 -84.2 ...
$ lat : num 10.6 10.6 10.6 10.6 10.6 ...
$ flagged : chr "false" "false" "false" "false" ...
$ analyses : int 1 1 1 1 1 1 1 1 1 1 ...
$ email : chr "moises.cruz@sinac.go.cr" "moises.cruz@sinac.go.cr" "moises.cruz@sinac.go.cr" "moises.cruz@sinac.go.cr" ...
$ collection_time : chr "44168,62778" "44168,62778" "44168,62778" "44168,62778" ...
$ analysis_duration : num 1147 1147 1147 1147 1147 ...
$ imagery_title : chr "Planet NICFI Public" "Planet NICFI Public" "Planet NICFI Public" "Planet NICFI Public" ...
$ imagery_attributions: logi NA NA NA NA NA NA ...
$ sample_geom : chr "POINT(-84.1666339410934 10.6368769527093)" "POINT(-84.1666339410934 10.6371884765137)" "POINT(-84.1666339410934 10.6375)" "POINT(-84.1666339410934 10.6378115231682)" ...
$ pl_plotid : int 0 0 0 0 0 0 0 0 0 0 ...
$ T1.COBERTURA : chr "T1C1000Vegetacion" "T1C1000Vegetacion" "T1C1000Vegetacion" "T1C1000Vegetacion" ...
$ X1000.Veget.T1 : chr "T1C1100Arboles" "T1C1100Arboles" "T1C1100Arboles" "T1C1100Arboles" ...
$ X2000.Sin.veg.T1 : chr "" "" "" "" ...
$ X3000.Agua.T1 : chr "" "" "" "" ...
$ X4000.Nub.somb.T1 : chr "" "" "" "" ...
$ T1.USO : chr "T1U1000MCbosques" "T1U1000MCbosques" "T1U1000MCbosques" "T1U1000MCbosques" ...
$ X1000.MC.bos.T1 : chr "T1U1100BosqueMad" "T1U1100BosqueMad" "T1U1100BosqueMad" "T1U1100BosqueMad" ...
$ X2000.Agricul.T1 : chr "" "" "" "" ...
$ X3000.Ganad.past.T1 : chr "" "" "" "" ...
$ X4000.Zon.hum.T1 : chr "" "" "" "" ...
$ X5000.Infraest.T1 : chr "" "" "" "" ...
$ X6000.Otras.tier.T1 : chr "" "" "" "" ...
$ X7000.No.clasif.T1 : chr "" "" "" "" ...
$ T2.COBERTURA : chr "T2C1000Vegetacion" "T2C1000Vegetacion" "T2C1000Vegetacion" "T2C1000Vegetacion" ...
$ X1000.Veget.T2 : chr "T2C1100Arboles" "T2C1100Arboles" "T2C1100Arboles" "T2C1100Arboles" ...
$ X2000.Sin.veget.T2 : chr "" "" "" "" ...
$ X3000.Agua.T2 : chr "" "" "" "" ...
$ X4000.Nub.somb.T2 : chr "" "" "" "" ...
$ T2.USO : chr "T2U1000MCbosques" "T2U1000MCbosques" "T2U1000MCbosques" "T2U1000MCbosques" ...
$ X1000.MC.bos.T2 : chr "T2U1100BosqueMad" "T2U1100BosqueMad" "T2U1100BosqueMad" "T2U1100BosqueMad" ...
$ X2000.Agricul.T2 : chr "" "" "" "" ...
$ X3000.Ganad.past.T2 : chr "" "" "" "" ...
$ X4000.Zonas.humed.T2: chr "" "" "" "" ...
$ X5000.Infraest.T2 : chr "" "" "" "" ...
$ X6000.Otras.tier.T2 : chr "" "" "" "" ...
$ X7000.No.clasif.T2 : chr "" "" "" "" ...
$ Ob.T1.COB : chr "" "" "" "" ...
$ Ob.T1.USO : chr "" "" "" "" ...
$ Ob.T2.COB : chr "" "" "" "" ...
$ Ob.T2.USO : chr "" "" "" "" ...La función summary() despliega información resumida para cada una de las columnas de un data frame.
# Despliegue de información resumida sobre las columnas de un data frame
summary(puntos_muestreo)
summary() puede ser aplicada específicamente en una o varias columnas de un data frame.
# Aplicación de summary() en columnas específicas de un data frame
summary(puntos_muestreo$plot_id, puntos_muestreo$sample_id, puntos_muestreo$analysis_duration)
Min. 1st Qu. Median Mean 3rd Qu. Max.
138527666 138527982 138528310 138528304 138528628 138528955 Funciones del paquete dplyr
El paquete dplyr es descrito en Tidyverse como una gramática para la manipulación de datos, la cual proporciona un conjunto consistente de verbos que ayuda a solucionar los retos de manipulación de datos más comunes. Los “verbos” (i.e. funciones) de esta gramática son:
filter(): selecciona observaciones con base en sus valores.
arrange(): cambia el orden de los registros.
select(): selecciona variables con base en sus nombres.
mulate(): crea nuevas variables como funciones de variables existentes.
summarise(): agrupa y resume valores múltiples.
Todas estas funciones trabajan de manera similar:
- El primer argumento es un data frame. Puede omitirse si la función recibe un data frame a través del operador pipe.
- Los argumentos siguientes describen que hacer con el data frame, utilizando los nombres de las variables (sin comillas).
- El resultado es un nuevo data frame.
filter()
filter() genera un subconjunto de observaciones con base en sus valores. El primer argumento es el nombre del data frame. Los argumentos subsiguientes son las expresiones lógicas que filtran el data frame.
Ejercicio:
a. Filtre los puntos de muestreo con cobertura (T1.COBERTURA) de vegetación y uso (T1.USO) de ganado y pastos.
arrange()
arrange() cambia el orden de las observaciones de un data frame. Como argumentos, recibe un data frame y un conjunto de nombres de columnas.
Ejercicio:
a. Filtre los puntos de muestreo con cobertura (T1.COBERTURA) de vegetación y ordénelos por la duración del análisis. Utilice pipes para encadenar las funciones.
select()
La función select() selecciona un subconjunto de las variables de un data frame.
mutation()
mutation() se utiliza para crear variables en función de otras.
summarise()
summarise() agrupa y resume valores múltiples.
En el siguiente ejemplo, agrupa todas las observaciones en un solo registro:
promedio_duracion_analisis
1 965.9127En combinación con group_by(), la agrupación puede ser realizada con base en otras variables.
puntos_muestreo %>%
group_by(T1.COBERTURA) %>%
summarise(promedio_duracion_x_cobertura = mean(analysis_duration, na.rm = TRUE))
# A tibble: 6 x 2
T1.COBERTURA promedio_duracion_x_cobertura
<chr> <dbl>
1 "" NaN
2 "T1C1000Vegetacion" 956.
3 "T1C2000SinVegetacion" 1684.
4 "T1C3000Agua" 776.
5 "T1C4000NubesYsombras" 685.
6 "T1C5000SinInformacion" 529. Ejercicio:
a. Utilice las funciones group_by() y count() para calcular la cantidad de puntos en cada parcela.
Análisis exploratorio de datos
Visualización de distribuciones
La distribución de una variable muestra la cantidad de veces que ocurre cada uno de sus posibles valores. Las variables se dividen en categóricas y contínuas.
Variables categóricas
Una variable es categórica si toma sus valores de un conjunto de datos limitado como, por ejemplo, un conjunto de hileras de caracteres correspondientes a algún tipo de clasificación.
Para conocer la distribución de una variable categórica, puede empezarse contando la cantidad de veces que ocurre cada categoría mediante la función count().
# Distribución de la variable T1.COBERTURA
puntos_muestreo %>%
count(T1.COBERTURA) %>%
arrange(desc(n))
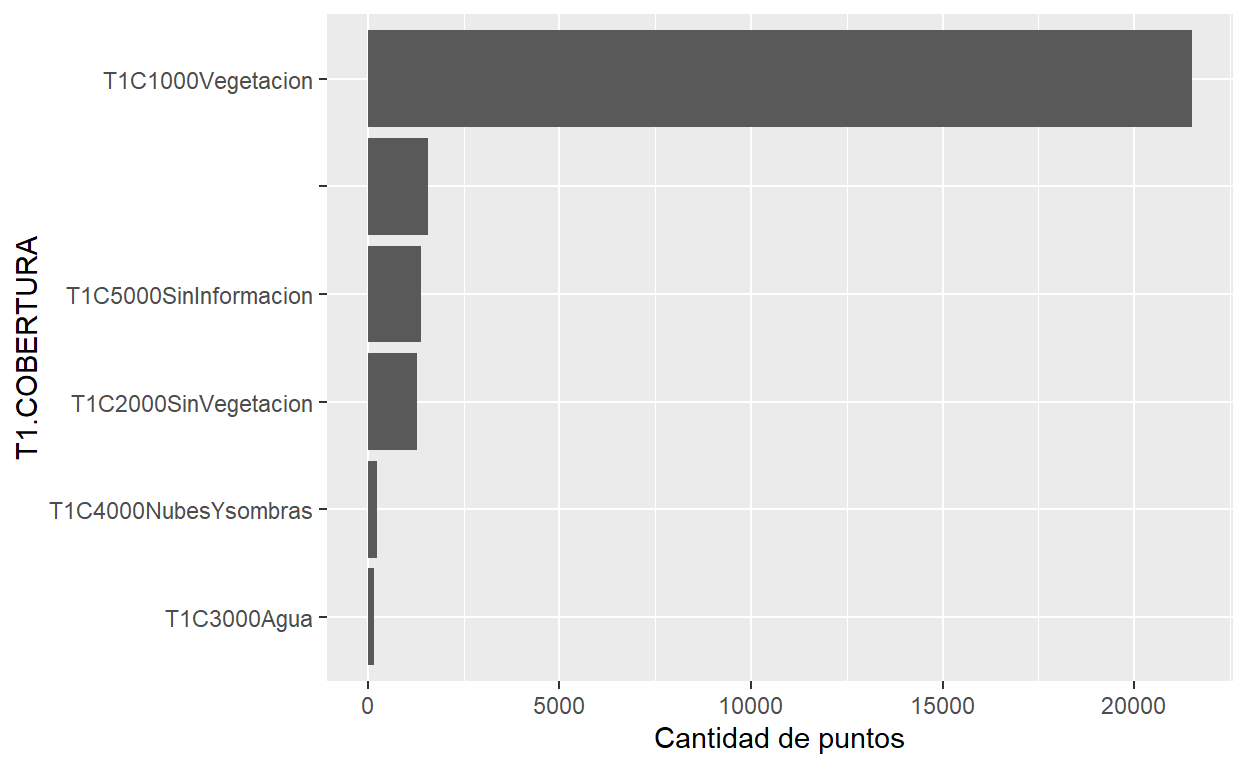
T1.COBERTURA n
1 T1C1000Vegetacion 21500
2 1575
3 T1C5000SinInformacion 1389
4 T1C2000SinVegetacion 1274
5 T1C4000NubesYsombras 233
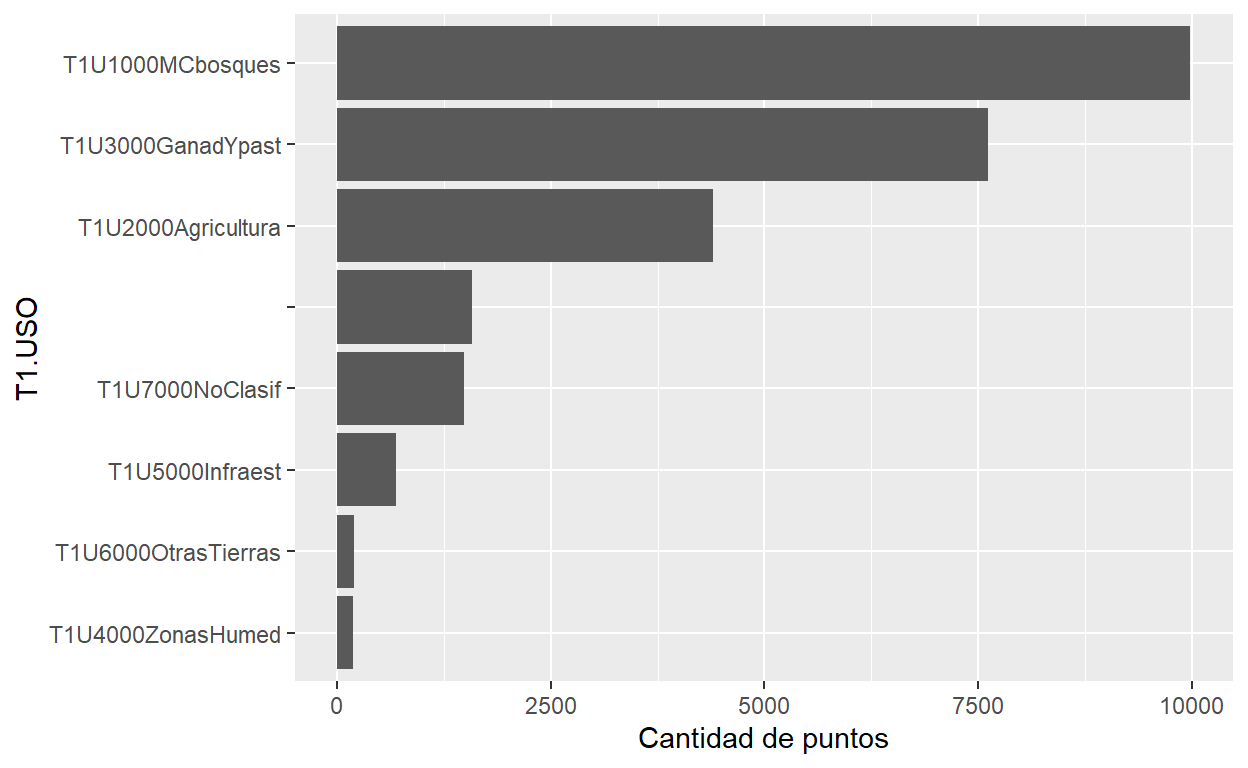
6 T1C3000Agua 154 T1.USO n
1 T1U1000MCbosques 9983
2 T1U3000GanadYpast 7616
3 T1U2000Agricultura 4393
4 1575
5 T1U7000NoClasif 1488
6 T1U5000Infraest 689
7 T1U6000OtrasTierras 200
8 T1U4000ZonasHumed 181Estas distribuciones puede graficarse mediante gráficos de barras.
# Distribución de la variable T1.COBERTURA
ggplot(puntos_muestreo, aes(x=reorder(T1.COBERTURA, T1.COBERTURA, length))) +
xlab("T1.COBERTURA") +
ylab("Cantidad de puntos") +
geom_bar() +
coord_flip()
# Distribución de la variable T1.USO
ggplot(puntos_muestreo, aes(x=reorder(T1.USO, T1.USO, length))) +
xlab("T1.USO") +
ylab("Cantidad de puntos") +
geom_bar() +
coord_flip()
Variables continuas
Una variable es continua si puede definirse en un conjunto infinito de valores ordenados. Intervalos de números y de tiempo son ejemplos de variables continuas.
Para analizar la distribución de una variable continua, puede utilizarse un histograma.
# Distribución de la variable analysis_duration
ggplot(data = puntos_muestreo) +
geom_histogram(mapping = aes(x = analysis_duration), binwidth = 1000)
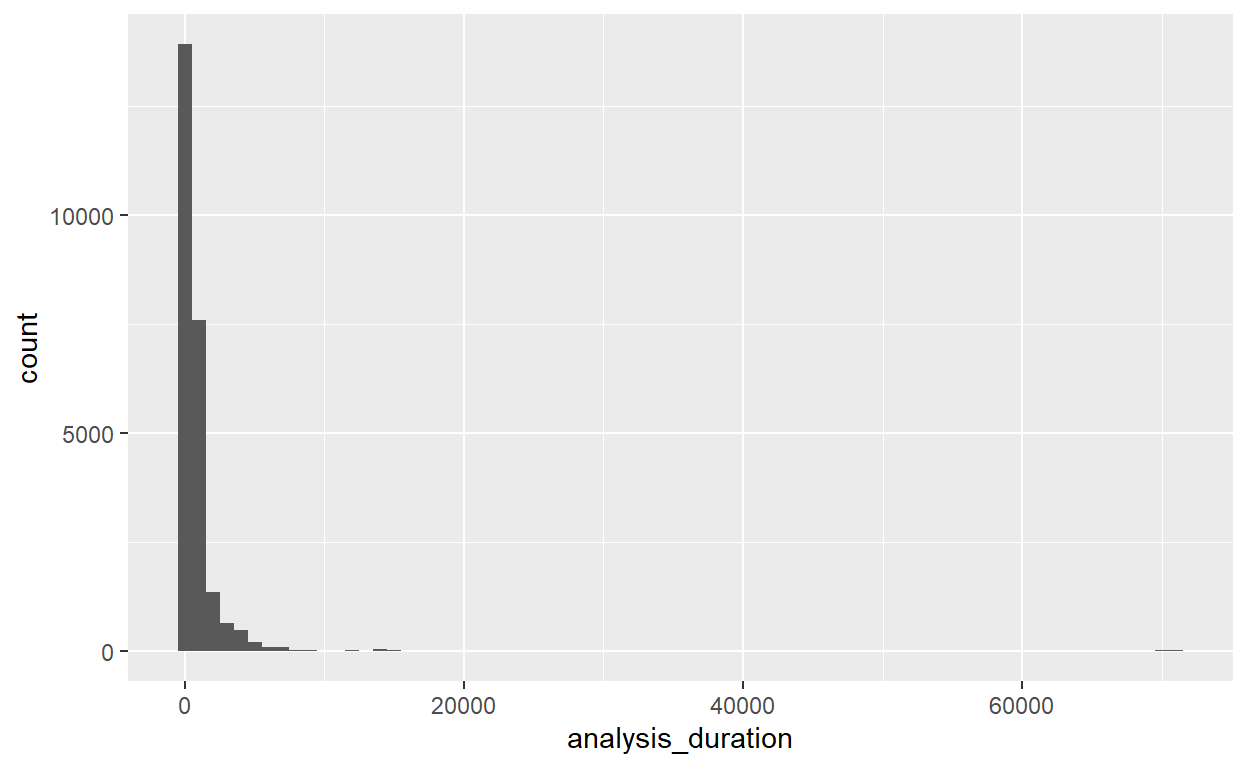
La cantidad de observaciones en cada bin puede calcularse mediante count() y cut_width().
# Distribución de la variable analysis_duration
puntos_muestreo %>%
count(cut_width(analysis_duration, 1000))
cut_width(analysis_duration, 1000) n
1 [-500,500] 13900
2 (500,1.5e+03] 7575
3 (1.5e+03,2.5e+03] 1350
4 (2.5e+03,3.5e+03] 650
5 (3.5e+03,4.5e+03] 475
6 (4.5e+03,5.5e+03] 200
7 (5.5e+03,6.5e+03] 100
8 (6.5e+03,7.5e+03] 100
9 (7.5e+03,8.5e+03] 25
10 (8.5e+03,9.5e+03] 25
11 (1.15e+04,1.25e+04] 25
12 (1.35e+04,1.45e+04] 50
13 (1.45e+04,1.55e+04] 25
14 (6.95e+04,7.05e+04] 25
15 (7.05e+04,7.15e+04] 25
16 <NA> 1575